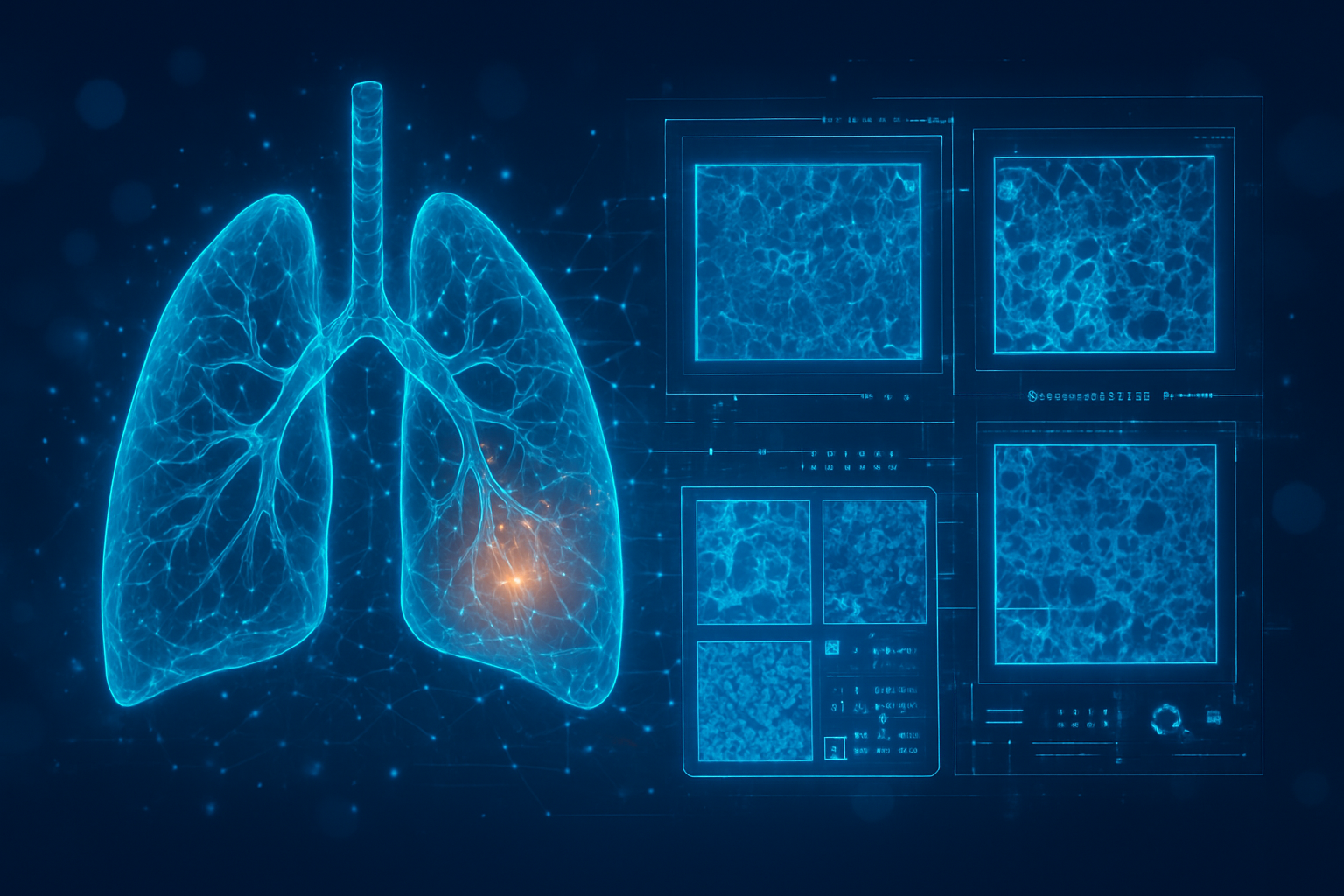
The landscape of oncology is undergoing a seismic shift as 2026 begins, driven by a new generation of artificial intelligence that identifies malignancy not by looking for tumors, but by predicting their inevitability. Two groundbreaking developments—the Sybil algorithm for lung cancer and the Prov-GigaPath foundation model for pathology—have moved from research laboratories into clinical validation, proving that AI can detect the biological signatures of cancer up to six years before they become visible on a standard scan or a microscope slide.
This evolution from reactive to predictive medicine marks a turning point in global health. By identifying "high-risk biological trajectories," these models allow clinicians to intervene during a "window of opportunity" that previously did not exist. For patients, this means the difference between a preventative procedure and a late-stage battle, potentially saving millions of lives through early detection that bypasses the inherent limitations of human perception.
Technical Deep Dive: Beyond Human Perception
The technical architecture of these breakthroughs represents a departure from traditional computer-aided detection (CAD). Sybil, developed by researchers at the MIT Jameel Clinic and Mass General Brigham, utilizes a 3D Convolutional Neural Network (CNN) to analyze the entire volumetric data of a low-dose CT (LDCT) scan. Unlike earlier systems that required human-annotated labels of visible nodules, Sybil operates autonomously, identifying subtle textural changes in lung tissue that indicate a high probability of future cancer. As of early 2026, Sybil has demonstrated an Area Under the Curve (AUC) of 0.94 for one-year predictions, successfully flagging patients who would otherwise be cleared by a human radiologist.
In parallel, Prov-GigaPath, a collaboration between Microsoft (NASDAQ: MSFT), Providence, and the University of Washington, has set a new benchmark for digital pathology. It is the first large-scale foundation model for whole-slide imaging, utilizing a Vision Transformer (ViT) with LongNet-based dilated self-attention. This allows the model to process a gigapixel pathology slide—containing tens of thousands of image tiles—as a single, contextual sequence. Trained on a staggering 1.3 billion image tiles, Prov-GigaPath can identify genetic mutations, such as EGFR variants in lung cancer, directly from standard H&E stained slides, bypassing the need for time-consuming and expensive molecular sequencing.
These advancements differ from previous technology by their scale and predictive window. While older AI could confirm a radiologist's suspicion of an existing mass, Sybil can predict cancer risk six years into the future with a C-index of up to 0.81. This "pre-clinical" detection capability has stunned the research community, with experts at the 2025 World Conference on Lung Cancer noting that AI is now effectively seeing "the invisible architecture of disease" before the disease has even fully manifested.
Industry & Market Impact: The Enterprise Infrastructure Race
The commercial implications of these breakthroughs are reshaping the medical technology sector. Microsoft (NASDAQ: MSFT) has solidified its position as the infrastructure backbone of the AI-driven clinic by releasing Prov-GigaPath as an open-weight model on the Azure Model Catalog. This strategic move encourages widespread adoption while positioning Azure as the primary cloud environment for the massive datasets required for digital pathology. Meanwhile, GE HealthCare (NASDAQ: GEHC) continues to dominate the regulatory landscape, recently surpassing 100 FDA clearances for AI-enabled devices. Their 16-year partnership with Nvidia (NASDAQ: NVDA) to develop autonomous imaging systems suggests a future where the AI isn't just an add-on, but an integrated part of the hardware's operating system.
Major medical device players like Siemens Healthineers (OTC: SMMNY) are also feeling the pressure to integrate these high-precision models. Siemens has responded by embedding AI clinical pathways into its photon-counting CT scanners, which provide the high-resolution data that models like Sybil require to function optimally. This has created a competitive "arms race" in the imaging market, where hardware sales are increasingly driven by the software's ability to provide predictive analytics. Startups in the Multi-Cancer Early Detection (MCED) space, such as Freenome and Grail, are also benefiting, as they partner with Nvidia to use its Blackwell GPU architecture to accelerate the identification of cancer signals in cell-free DNA.
The disruption is most evident in the diagnostic workflow. PathAI and other digital pathology leaders have seen their roles expand as the FDA granted new clearances in late 2025 for primary AI-driven diagnosis. This shift threatens the traditional business models of diagnostic labs that rely on manual slide reviews, forcing a rapid transition to digital-first environments where AI foundation models perform the heavy lifting of initial screening and mutation prediction.
Broader Significance: Shifting the Paradigm of Prevention
Beyond the technical and commercial success, the rise of Sybil and Prov-GigaPath carries immense social and ethical weight. It fits into a broader trend of "foundation models for everything," mirroring the impact that models like AlphaFold had on protein folding. For the first time, the AI landscape is moving toward a "total health" view, where data from radiology, pathology, and genomics are synthesized by multimodal agents to provide a unified patient risk profile. This mirrors the trajectory of Google (NASDAQ: GOOGL) and its "Capricorn" tool, which aims to personalize pediatric oncology through agentic AI.
However, this shift raises significant concerns regarding overdiagnosis and equity. As AI becomes more sensitive, the medical community must grapple with "incidentalomas"—small anomalies that may never have progressed to clinical disease but lead to patient anxiety and unnecessary invasive procedures. There is also the critical issue of bias; however, recent 2026 validation studies have shown Sybil to be "race- and ethnicity-agnostic," performing with equal accuracy across diverse populations, a significant milestone compared to previous medical algorithms that often failed under-represented groups.
The potential impact on global health is profound. In regions with a chronic shortage of radiologists and pathologists, these AI models act as "force multipliers." By January 2026, the MIT Jameel Clinic AI Hospital Network had deployed Sybil in 25 hospitals across 11 countries, demonstrating that advanced predictive care can be scaled to underserved populations, potentially narrowing the health equity gap in oncology.
The Road Ahead: Temporal Tracking and Multi-Modal Integration
Looking forward, the next frontier for these models is temporal tracking. In December 2025, researchers introduced GigaTIME, an evolution of the Prov-GigaPath model designed to track the evolution of the tumor microenvironment over months or years. This "time-series" approach to pathology will allow doctors to see how a patient’s cancer is responding to treatment in near real-time, adjusting therapies before physical symptoms of resistance emerge. Experts predict that within the next 24 months, the integration of AI into Electronic Medical Records (EMRs) will become standard, with "predictive alerts" automatically appearing for primary care physicians.
Challenges remain, particularly in data privacy and the integration of these tools into fragmented hospital IT systems. The industry is closely watching for the upcoming FDA decision on blood-based multi-cancer tests, which, when combined with imaging AI like Sybil, could create a "dual-check" system for early detection. The goal is a world where "late-stage cancer" becomes a rare occurrence, replaced by "early-stage interception."
Conclusion: A New Era in Diagnostic History
The breakthroughs of Sybil and Prov-GigaPath represent more than just incremental improvements in medical software; they are the harbingers of a new era in human biology. By identifying the fingerprints of cancer years before they are visible to human eyes, AI has effectively expanded the human sensory range, giving us a strategic advantage in a war that has been fought reactively for decades. The transition to this predictive model of care will require new regulatory frameworks and a shift in how we define "diagnosis."
As we move through 2026, the key developments to watch will be the large-scale longitudinal results from hospitals currently using these models and the potential for a unified foundation model that combines radiology, pathology, and genetics into a single "diagnostic oracle." For now, the silent sentinel of AI is watching, identifying the risks of tomorrow in the scans of today.
This content is intended for informational purposes only and represents analysis of current AI developments.
TokenRing AI delivers enterprise-grade solutions for multi-agent AI workflow orchestration, AI-powered development tools, and seamless remote collaboration platforms.
For more information, visit https://www.tokenring.ai/.
